Рассмотрим общее устройство PostgreSQL. А именно как с ним взаимодействует клиент, его особенности. Рассмотрим работу его процессов и то как они взаимодействуют с памятью. Дополнительно можете почитать документацию.
Клиент серверная работа PostgreSQL
PostgreSQL эта сервер который обслуживает базы данных SQl. К нему подключаются клиенты и с помощью SQL запросов работают с этими базами. Клиентские приложения могут быть расположены на сервере приложений или прямо на компьютере пользователя.
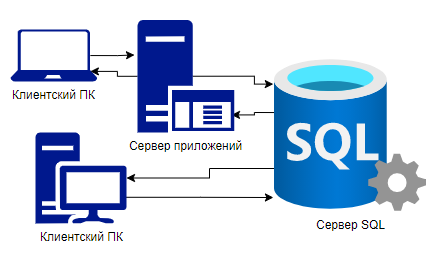
Клиент — это какое-то приложение, например psql. Клиент с сервером общается по определённому протоколу. Протокол у PostgreSQL открытый, но для каждого приложения его не нужно реализовывать. Обычно используют стандартные библиотеки и драйверы. Основная библиотека это libpq, её использует psql и все штатные утилиты PostgreSQL. Для многих языков программирования есть свои библиотеки, которые основаны на libpq.
Алгоритм работы с сервером примерно такой:
- клиент подключается к серверу, а сервер выполняет его аутентификацию;
- клиент формирует запросы, а сервер их выполняет и возвращает результаты;
- дополнительно клиент управляет транзакциями, а сервер обеспечивает их поддержку.
Транзакции SQL
Транзакция — это группа последовательных операций с базой данных, которые выполняются как одна операция.
Транзакция имеет определённые требования:
- Атомарность — это означает что транзакция всегда выполняется полностью, или не выполняется вообще. Это гарантирует что все операции в транзакции будут успешно завершены. А если не будут, то транзакция откатив все предыдущие операции и база вернется в исходное состояние. Другими словами, нельзя выполнить транзакцию наполовину.
- Согласованность — предполагается что база до выполнения транзакции находится в одном согласованном состоянии. Согласованность гарантирует что после выполнения транзакции база должна перейти в другое согласованное состояние, или вернуться в прежнее.
- Изолированность — это свойство позволяет транзакциям работать независимо друг от друга. Две параллельные транзакции должны отработать, как будто выполнялись последовательно.
- Долговечность — гарантирует, что результат совершенной транзакции сохранится в случае сбоя системы.
За выполнение атомарности, согласованности и изолированности отвечает много-версионность. За долговечностью следит другой механизм — журнал.
Выполнение запроса
Запрос в процессе своего выполнения проходит 4 стадии:
- Разбор. Система определяет корректность запроса. Он должен быть синтактически правильным и все объекты к которым он обращается должны существовать. Также к этим объектам должны быть права доступа. Для разбора PostgreSQL хранит системные каталоги — это такое место, где СУБД хранит информацию о таблицах и столбцах и служебные сведения. Системные каталоги это обычные таблицы. Поэтому вы можете удалить и пересоздать их, добавить столбцы, изменить и добавить строки, то есть разными способами вмешаться в работу системы.
- Трансформация. В PostgreSQL есть механизм правил, с помощью которых можно немного изменить запрос. Например если вы ссылаетесь на какое-нибудь представление, то имя представления с помощью правил трансформируется в запрос, который стоит за этим представлением. После трансформации получается более низкоуровневый запрос.
- Планирование. Когда мы пишем запрос на SQL, мы говорим что хотим получить, а не как это сделать. За то «как это сделать» отвечает планировщик основываясь на статистике. Статистика включает в себя: сколько у нас таблиц, сколько в них строчек, сколько они занимают страниц, как распределены данные в столбцах и тому подобное. Планировщик решает с каких таблиц начать выполнение запроса, какие условия и в каком порядке применять и так далее. Планировщик подготавливает план выполнения.
- Выполнение. И наконец, когда построен план выполнения, начинается работа с данными.
После выполнения запроса его результат отдаётся клиенту. Обычно результат отдается целиком, но можно использовать так называемые курсоры, чтобы отдавать результат построчно. Курсор вначале нужно открыть, затем с помощью команды FETCH мы построчно получаем результат запроса и в конце закрываем курсор.
Еще в PostgreSQL есть механизм подготовки оператора. Мы заранее можем провести разбор и трансформацию и сохранить такой разобранный запрос. Дальше, для подготовленного оператора вы задаёте фактические параметры и запрос минуя разбор и трансформацию сразу начинает планироваться с этими параметрами. Если у запроса нет параметров, то и план запроса сохраняется и сразу начинается выполнение.
Процессы и память
Процессов на сервере PostgreSQL много, но выделяют три вида:
- Основной процесс, раньше назывался Postmaster, сейчас просто Postgres. Он слушает назначенный порт и по необходимости запускает другие процессы: фоновые или обслуживающие. Когда клиентское приложение хочет подключиться, то основной процесс запускает обслуживающий процесс и подключает приложение к нему.
- Обслуживающие процессы. Работает с клиентом (отвечает за обработку его запросов). У этого процесса есть локальная память для хранения подготовленных операторов (разобранных запросов), курсоров и другого. Сколько клиентов подключаются к серверу, столько и обслуживающих процессов создается.
- Фоновые процессы. Выполняют различные служебные операции, например очищают базу от уже неактуальных данных.
Память выделяемая для работы PostgreSQL тоже бывает разных типов:
- Локальная память процесса. Необходима обслуживающему процессу для хранения подготовленных операторов, курсоров, различных переменных окружения и тому подобное. В эту память входит и так называемая WorkMem память, которая используется для внутренних операций.
- Общая память. В ней хранятся фактические данные, то есть таблицы базы данных. Все процессы взаимодействуют с базой данных и друг с другом через эту память. Так эта память общая для всех процессов, то к ней применяют механизм блокировок. Если 1 процесс работает с какой-то структурой данных он должен её заблокировать от других процессов.
Пулы соединений
Чтобы уменьшить потребление памяти, иногда используют пулы соединений. Между клиентом и сервером работает менеджер пула. Он открывает несколько соединений с базой данных и держит их. А все клиентские соединения работают с базой данных через этот менеджер пула. Так получается уменьшить количество обслуживающих процессов и соединений, а значит экономится оперативная память.
Встроенного пула в PostgreSQL нет, но клиент сам может его реализовать.
Двойная буферизация PostgreSQL
Напрямую к дискам PostgreSQL не обращается, а обращается используя ОС. В Linux все что читается или пишется на диск всегда проходит дисковый кэш. Например прочитали вы файлик, он попал в кэш (в оперативную память), следующий раз при обращении к этому файлу он будет читаться из кэша а не с диска.
Получается, выполнили вы запрос, некоторые таблички были прочитаны с диска и попали в дисковый кэш. Из кэша PostgreSQL забрал из в общую память, чтобы поработать с табличками. Получается данные дублируются в оперативной памяти. Это не очень хорошо, но нужно знать про эту особенность работы PostgreSQL.
Надежность PostgreSQL при сбоях
Чтобы гарантировать восстановление после сбоя PostgreSQL использует журнал предварительной записи — WAL. Этот журнал позволяет после сбоя восстановить согласованность данных. Подробнее разберу его позже, а пока просто запомните, что такой механизм присутствует.
Расширяемость PostgreSQL
Так как PostgreSQL это база с открытым исходным кодом, её можно дописать под себя. Но PostgreSQL позволяет многое в себя добавить не меняя код ядра с помощью расширений. Расширения позволяют создавать новые типы данных, новые типы индексов, новые функции, операторы и другое. Также можно создавать свои фоновые процессы.
Дополнительно к вышесказанному, к базе данных можно подключать внешние источники данных. Например, подключить к базе данных файл и работать с ним как с таблицей.
