В этой статье мы разбираем многопоточность в Python 3. Вспомним про GIL, рассмотрим модуль threading и его классы Thread, Timer и Rlock.
Введение
Когда мы запускаем обычную (однопоточную) программу, то запускается один процесс, который содержит 1 поток. Именно поток выполняет полезную работу на процессоре. В одном процессе может выполнятся сразу несколько потоков. И потоки могут выполняться на разных ядрах процессора одновременно. Включив в Python коде многопоточность, мы можем распараллелить некоторые задачи, но не все из-за ограничений GIL.
Ограничения GIL
Python 3 позволяет писать многопоточные приложения с помощью модуля threading. Но потоки подвержены блокировкам GIL, который позволяет работать с интерпретатором 1 потоку в 1 момент времени.
Представьте что у вас запущено 2 потока одного приложения. Первый поток начинает работать с ЦПУ и GIL блокирует интерпретатор для второго потока. Второй поток хочет поработать с ЦПУ, но GIL его туда не пускает. Через промежуток времени первый поток ставит свою работу на паузу и GIL разрешает поработать второму потоку.
Так как такие промежутки времени очень малы, то мы думаем что потоки работают параллельно. Но на самом деле, они работают по очереди.
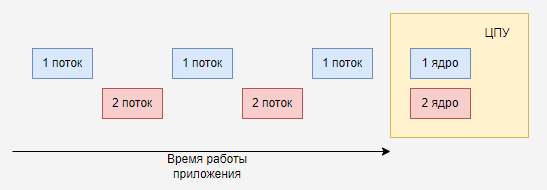
И даже, если потоки работают на разных ядрах процессора, то всё равно из-за GIL они работают по очереди.
Но даже в этом случае иногда применяют многопоточность в коде Python 3, например в одном потоке работает основна программа, а во втором проверяется её лицензионный ключ. Нам не важно что эти потоки будут работать по очереди. Мы даже не заметим переключения между потоками.
Потоки в разных процессах могут работать параллельно на разных ядрах процессора, потому что для каждого процесса создаётся свой GIL. Но процессы потребляют больше ресурсов. О многопроцессорном программировании я напишу отдельную статью.
Что GIL не блокирует
Настоящая многопоточность в Python 3 всё же присутствует. Потоки могут обращаться не только к центральному процессору, но и к подсистеме ввода вывода (работа с файлами и http-запросами). За такой работой GIL не следит, и здесь уже работает настоящее распараллеливание. А ещё GIL не следит за чтением и изменением чисел (целых или с плавающей точкой). И именно в этих случаях потоки работают параллельно. Но нам придётся самим управлять блокировками, чтобы два потока работали согласованно с одним объектом.
Дополнительные потоки
Для создания дополнительных потоков используется модуль threading. А сам поток создаётся с помощью класса Thread. Для демонстрации создания дополнительных потоков напишем демо-программу. Здесь я буду писать код частями, а ниже покажу как этот код отработает.
Начнем мы с импорта необходимых модулей. Из модуля time нам понадобятся классы sleep (позволяет программе уснуть на указанное время) и time (для получения текущего времени). А из модуля threading мы возьмём класс Thread (для создания потоков).
from time import sleep, time from threading import Thread
Напишем функцию, которая будет выводить информацию о том что она запустилась, ждать указанное число секунд и писать что она остановилась.
def my_sleep(sec, name):
print("Запустился", name, "ждём", sec, "сек")
sleep(sec)
print("Остановился", name)
Создаём новый объект класса Thread (то есть новый поток). Ему нужно передать в параметр target функцию, которую мы хотим запустить в дополнительном потоке. А в параметре args — передать массив аргументов функции.
t1 = Thread(target=my_sleep, args=(10, 'Поток t1'))
Дальше запомним в переменной a1 текущее время и запустим наш процесс с помощью метода start().
a1 = time() t1.start()
Теперь выполним функцию в основном потоке программы:
my_sleep(5, 'Основной поток программы')
В переменной a2 запомним текущее время и узнаем сколько времени работала программа. Затем выведем этот результат:
a2 = time()
res = round((a2 - a1))
print("Работа основной программы завершена за", res, "сек")
Результат выполнения нашей программы:
Запустился Поток t1 ждём 10 сек Запустился Основной поток программы ждём 5 сек Остановился Основной поток программы Работа основной программы завершена за 5 сек Остановился Поток t1
В итоге у нас запускается функция в дополнительном потоке, она должен ждать 10 секунд. И пока она ждёт 10 секунд запускается функция в основном потоке программы. Функция из основного потока ждёт 5 секунд (а в это время, в дополнительном потоке, функция ждёт 10 секунд). Через 5 секунд завершается работа функции из основного потока (мы видим об этом сообщение). Дальше завершается работа основной программы, но через 10 секунд мы видим что функция в дополнительном потоке выполнила свою работу. То есть реальное время работы программы 10 секунд, вместо 15.
Потоки демоны
Потоки можно создавать как демоны. Такие потоки будут завершаться сразу как завершиться основной поток программы.
Для создания такого потока нужно добавить опцию daemon=True при создании потока:
t1 = Thread(target=my_sleep, args=(10, 'Поток t1'), daemon=True)
Изменим предыдущую программу и выполним её:
Запустился Поток t1 ждём 10 сек Запустился Основной поток программы ждём 5 сек Остановился Основной поток программы Работа основной программы завершена за 5 сек
Здесь дополнительный поток не успел доработать и был убит пока спал.
Ожидание завершения потока
Еще мы можем указать что нужно дожидаться выполнения дополнительного потока и только потом выполнять код основного потока, делается это с помощью метода join(), который нужно вызвать в том месте программы, где мы хотим дождаться выполнения.
Например, если мы запустим поток и сразу же скажем ожидать его выполнения:
t1.start() # эта строчка уже была, после неё добавим join() t1.join()
То код отработает так:
Запустился Поток t1 ждём 10 сек Остановился Поток t1 Запустился Основной поток программы ждём 5 сек Остановился Основной поток программы Работа основной программы завершена за 15 сек
Или можем поместить метод join() после запуска функции из основного потока:
my_sleep(5, 'Основной поток программы') # эта строчка уже была, после неё добавим join() t1.join()
Выполнение программы изменится:
Запустился Поток t1 ждём 10 сек Запустился Основной поток программы ждём 5 сек Остановился Основной поток программы Остановился Поток t1 Работа основной программы завершена за 10 сек
Хоть поток запущен как демон и должен был умереть вместе с основным потоком, но мы его подождали с помощью join().
Таймеры
Таймер это объект, который запускает дополнительный поток, но с отсрочкой по времени. Для демонстрации таймера можно использовать предыдущий пример кода. Но будем создавать не поток, а таймер.
Для этого вместо импорта Thread, импортируем Timer. И создадим объект класса Timer. А запускается таймер также как и Thread, с помощью метода start().
Вот переделанный код программы:
from time import sleep, time
from threading import Timer
def my_sleep(sec, name):
print("Запустился", name, "ждём", sec, "сек")
sleep(sec)
print("Остановился", name)
t1 = Timer(2, my_sleep, args=(10, 'Поток t1'))
a1 = time()
t1.start()
my_sleep(5, 'Основной поток программы')
t1.join()
a2 = time()
res = round((a2 - a1))
print("Работа основной программы завершена за", res, "сек")
Создавая объект класса Timer ему нужно указать задержку (в моём примере 2 секунды), и функцию вместе с параметрами.
Результат выполнения данной программы:
Запустился Основной поток программы ждём 5 сек Запустился Поток t1 ждём 10 сек Остановился Основной поток программы Остановился Поток t1 Работа основной программы завершена за 12 сек
То есть таймер, это как поток, но запускается через указанный промежуток времени.
Блокировки
До сих пор мы работали с методом sleep(), он не подвержен GIL, поэтому ждать потоки могут параллельно. А так как при ожидании мы не меняем никакие объекты, то и думать о блокировках нам не приходилось.
Но потоками мы можем что-то изменять. И если мы изменяем файлы или числовую переменную, то GIL не блокирует поток. А это означает что 2-а потока могут попытаться изменить эту переменную одновременно. И в этом случае нам самим нужно думать о блокировке этого объекта.
Для создания блокировки мы можем использовать объект класса Lock или Rlock. Классы похожие, но при Lock разные потоки могут блокировать и разблокировать объекты. А при Rlock — только тот поток может снять блокировку, который её установил. В примере ниже можно использовать любой класс, код сработает одинаково.
Чтобы показать проблему отсутствия блокировок, напишем код. Для начала импортируем необходимые модули:
from time import sleep from threading import Thread
Установим начальное значение для переменной value:
value = 0
Напишем функцию которая будет менять значение глобальное переменной (value). Пока значение переменной меньше 10, увеличиваем это значение на 1, ждём 1 секунду и выводим значение переменной.
def inc_value():
global value
while value < 10:
value += 1
sleep(1)
print(value)
Создадим два потока и запустим их:
t1 = Thread(target=inc_value) t2 = Thread(target=inc_value) t1.start() t2.start()
Результат работы этой программы:
2 2 4 4 6 6 8 8 10 10
Как видим переменная увеличивается на 2, а не на 1. Это происходим потому что первый поток меняет 0 на 1, второй поток меняет 1 на 2. Затем первый поток выводит 2 и второй поток выводит 2. И так в цикле до 10.
Но мы можем использовать блокировки чтобы пока первый поток изменял переменную, второй поток ожидал в очереди.
Полный код программы с блокировками:
from time import sleep
from threading import Thread, RLock
value = 0
loc = RLock()
def inc_value():
global value
while value < 10:
loc.acquire()
value += 1
sleep(1)
print(value)
loc.release()
t1 = Thread(target=inc_value)
t2 = Thread(target=inc_value)
t1.start()
t2.start()
То есть мы дополнительно импортировали класс RLock, создали объект loc этого класса. И в начале цикла производим блокировку (методом acquire()), а в конце цикла снимаем блокировку(методом release()).
Результат работы этой программы:
1 2 3 4 5 6 7 8 9 10 11
Почему мы дошли до 11? Да потому что оба потока зашли в цикл, когда значение переменной было 9. Дальше первый поток сделал блокировку, увеличил число до 10 и снял блокировку. Второй поток уже находился в цикле и не выполняя проверку (value < 10) поставил блокировку, увеличил число до 11 и снял блокировку.
Итог
Мы познакомились с многопоточным программированием. Поняли что в некоторых случаях потоки блокируются GIL, а в некоторых не блокируются. А иногда нам нужно самим следить за блокировками.
Узнали про классы Thread, Timer и RLock модуля threading. Научились создавать объекты этих классов и использовать блокировки.
Остальные статье по Python 3 можете посмотреть здесь.
